Part 1 — Clean it yourself in Excel 25 pts
You will import the messy JEA Detail.txt into Excel, strip out everything that is not real data, and end with a clean ten-column table plus a count of journal entries for each user. Follow the steps as written — that exactness is the point. Power Query may be new to you. That is expected — the steps below assume no prior experience with it; do them in order. The Week 2 webinar also includes a short Power Query walkthrough and lab hints.
Look at the file first
Before Excel, open JEA Detail.txt in a plain-text editor — VS Code if you have it (preferred), otherwise Notepad on Windows or TextEdit on Mac. Just look. You are checking two things.
- What is wrong with the data — see the list below.
- The file's encoding. Every text file has an encoding — the system that turns stored bytes into readable characters. Your editor names it: in VS Code, in the blue bar at the bottom-right; in Notepad, in the status bar at the bottom, the second item from the right. You are looking for a short label such as
UTF-16 LE,UTF-8, orANSI. Write down exactly the one your editor shows — this file is not the usualUTF-8. You will need it in Part 2, and an import that assumes the wrong encoding fails before it reads a single row. New to the idea of encodings? Read the short encoding primer posted in this Week 2 module.
The file is a tab-separated export with several deliberate problems:
- A report header. Several lines at the top —
Company XYZ,REPORT DATE,GENERAL LEDGER DETAIL, a row of====— before the real data starts. - A two-line column header. The column names are split across two rows: an upper line carrying the longer labels (
Account,Post,User,Transaction), and a lower, complete line (Account,Category,Date,Period,ID, and the rest). Only the lower line is the one to keep. - Page-break rows. A handful of times in the data, the export inserts two non-data rows where a printed report would break to a new page — a row of
====and a row readingPAGE 0002(and so on). They sit scattered in the data and must come out. - Quoted, spaced amounts. The
Amountvalues are wrapped in quotes and padding spaces, with a thousands comma:" 50,000.00 "instead of a clean number. - A hidden character in the ID column. Some
IDcells begin with an invisible non-printing character — a stray line break. The value displays as blank or pushed out of place, so the user looks like missing data. Excel'sCLEANfunction removes these characters;TRIMdoes not, becauseTRIMonly removes spaces.
Underneath all of that are ten real columns: Account, Category, Date, Period, ID, Manual, Description, Number, Location, Amount.
No Excel? Read this first.
Excel is the intended tool for Part 1. If you do not have it, Google Sheets is an allowed substitute — use File → Import → Upload, choose tab as the separator, and follow the same logic (delete the header lines, delete the repeating page-break rows, keep the ten real columns, count entries per user). The screenshots will look slightly different but the task is identical. You can also check out a laptop with Excel from the University Library.
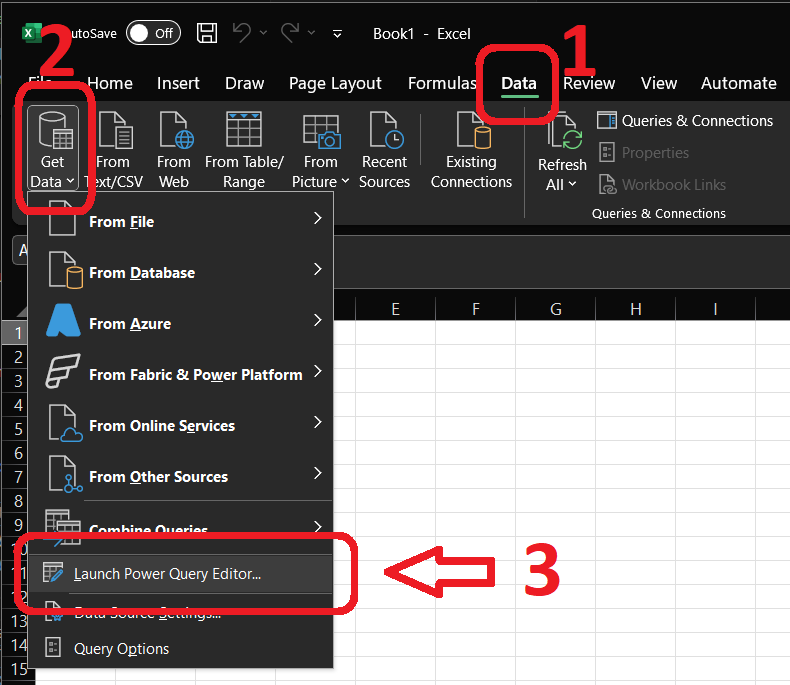
1.1 — Open Power Query and point it at the file
In Excel, go to the Data tab and choose Get Data → From File → From Text/CSV. This opens Power Query, Excel's import-and-transform tool.
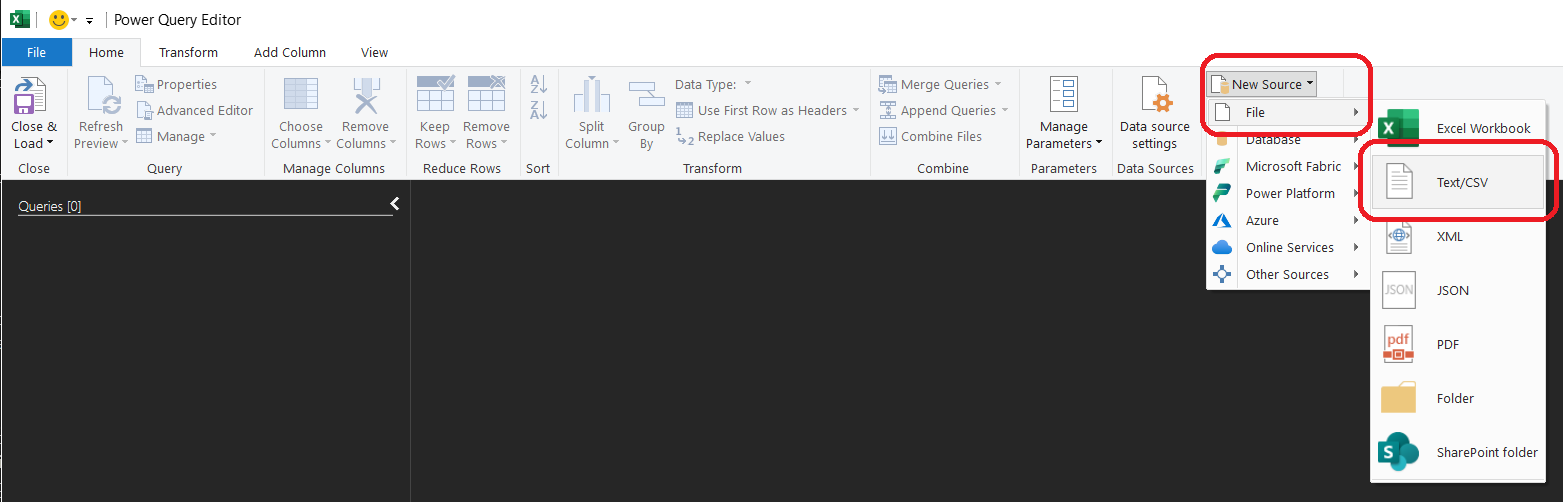
1.2 — Select JEA Detail.txt
Browse to the JEA Detail.txt file you downloaded and open it.
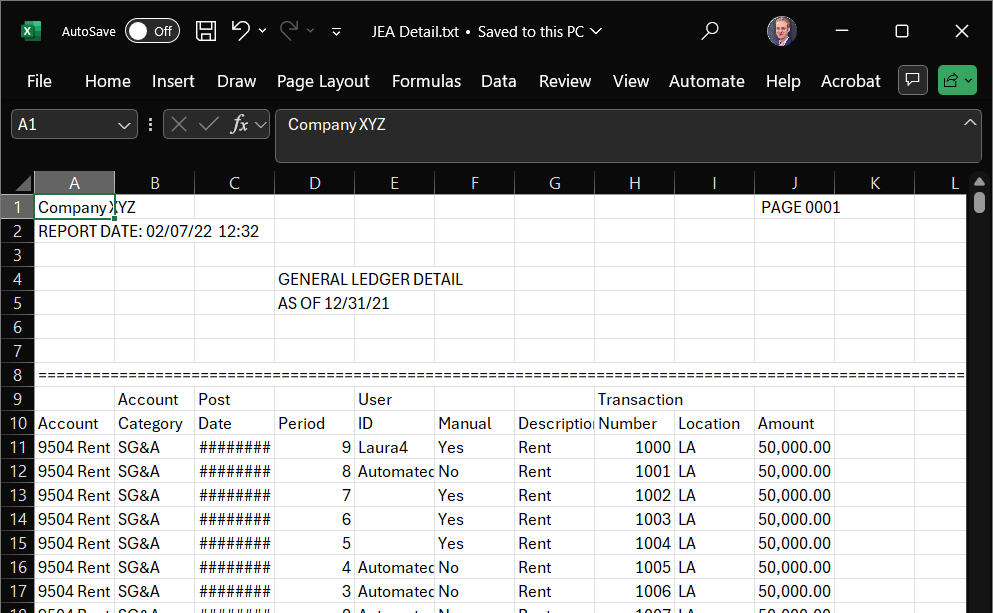
1.3 — Check the import preview
Power Query shows a preview. Confirm the delimiter is set to Tab. Notice the File Origin box near the top of the preview — that is the encoding, and Power Query detected it for you automatically. Remember that it had to be set; in Part 2 nothing will detect it for you. You will see the messy header lines at the top — that is expected. Click Transform Data (not Load) to open the Power Query editor.
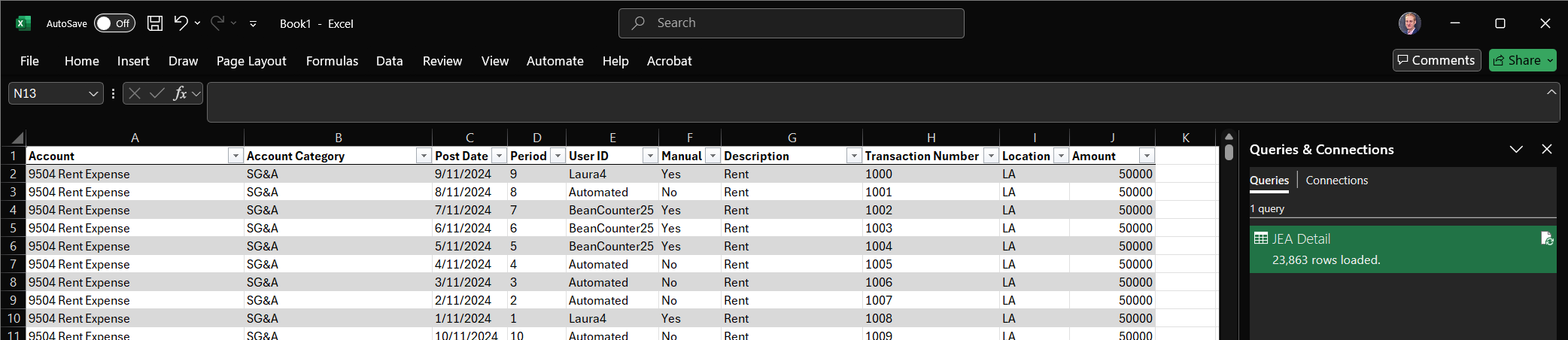
1.4 — See the raw data in the editor
The Power Query editor now shows every row, including the junk. The first several rows are the report header; somewhere below them the real column headers and data begin.
1.5 — Remove the report header and the extra header line
Two things sit above the real data: the report header, and then the upper of the file's two header lines. On the Home tab, use Remove Rows → Remove Top Rows and remove every row down to — but not including — the lower, complete column-header line, the one that reads Account, Category, Date, Period, ID, Manual, Description, Number, Location, Amount. Leave that complete line as the first row.
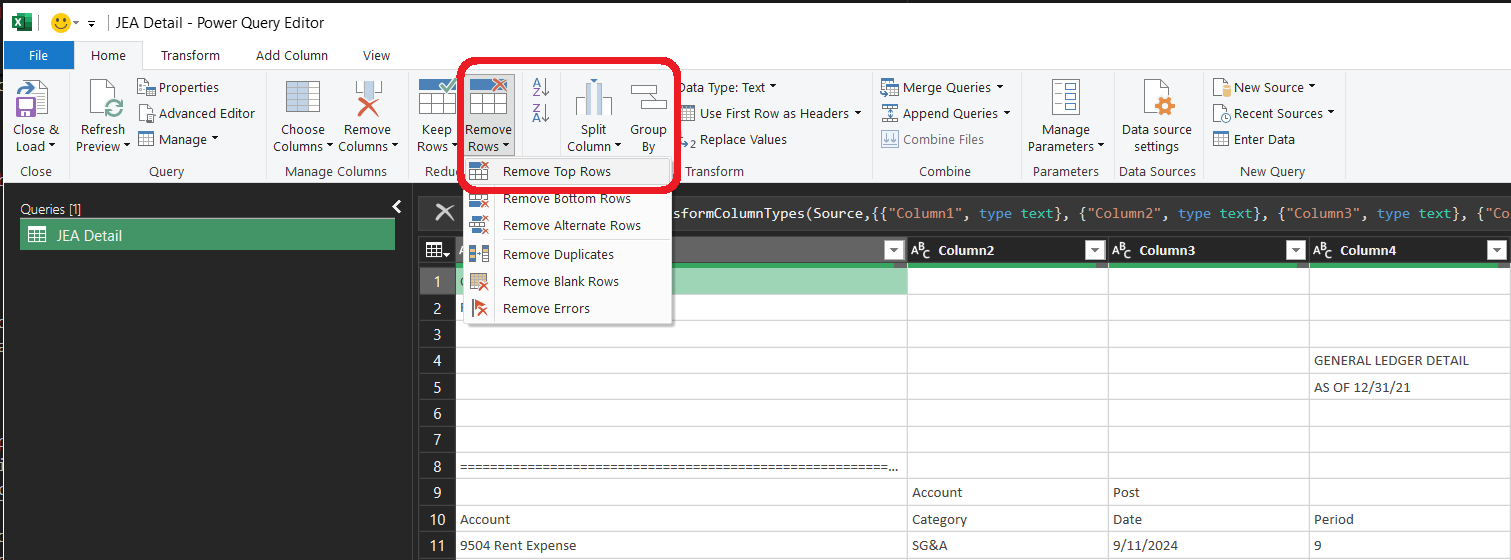
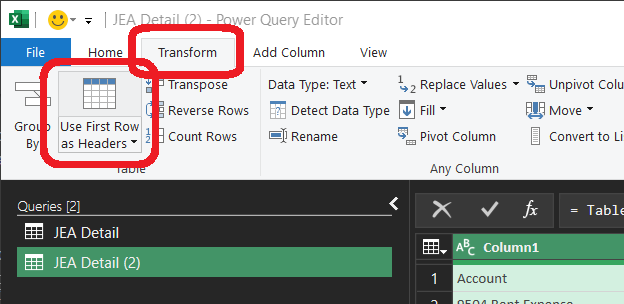
1.6 — Promote the header row
The first remaining row is now the complete column-header line. Use Use First Row as Headers so Account, Category, ID, Amount and the rest become actual column names instead of data.
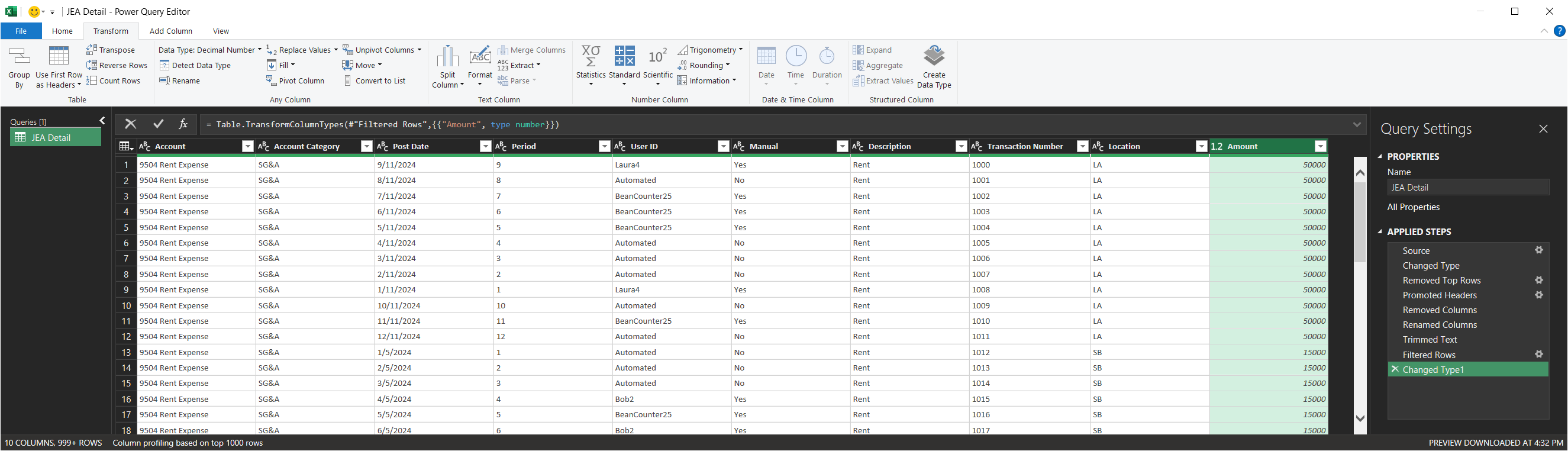
1.7 — Remove the page-break rows, fix the columns, and load
The page-break rows are scattered through the data — each is a row of ==== or a row reading PAGE and a number, with the rest of that row empty. The simplest way to drop them: pick a column that a real journal entry always fills — Category works well — and Filter it to remove the blank (null) rows. The page-break rows have nothing in that column, so they fall out; real entries stay. Then set each column's data type: click the small data-type icon to the left of the column name in its header, and choose the type — Amount to Decimal Number, the date column to Date. Setting Amount to a number is the step that strips the quotes, spaces, and comma from values like " 50,000.00 ", so do not skip it. When the step list on the right looks complete, click Close & Load.
1.8 — Count the journal entries for each user
On your cleaned table, you now need a count of how many journal entries belong to each user — the ID column. The straightforward way is a PivotTable: select your table, choose Insert → PivotTable, put ID in the Rows area and ID again in the Values area (it will summarize as Count). You get one row per user with a count beside it.
ID cells begin with an invisible non-printing character. In the PivotTable that user shows up with a blank or broken-looking label — the count beside it is right, but you cannot tell whose it is. Clean the ID column first (Excel's CLEAN function removes non-printing characters; TRIM alone will not, because TRIM only removes spaces). Note this trap — your Part 2 specification has to mention it.
New to PivotTables? There is a short practice tool in this Week 2 module, and the Week 2 lecture covers them.
ID and its number of journal entries). You will upload that workbook file (.xlsx) to the Lab 2 quiz — if you used Google Sheets, download it first with File → Download → Microsoft Excel (.xlsx). Keep the per-user count where you can see it: that small table is the by-hand result you hold the AI's work against in Part 2.
ID — both saved in the workbook you will upload to the Lab 2 quiz.